4 Echantillonnage aléatoire simple
4.1 Définition
Les unités sont sélectionnées avec une probabilité égale et indépendamment les unes des autres ; également appelé “échantillonnage aléatoire indépendant (IRS)”
Deux sous-types :
avec remise (SIR)
sans remise (SI)
Cette distinction n’est pas pertinente pour des populations infinies
Toutes les combinaisons de \(n\) unités de population (tous les échantillons de \(n\) unités) ont une probabilité égale d’être sélectionnés
4.2 Mise en oeuvre avec un logiciel
4.2.1 Pour les polutations discrètes
4.2.1.1 Excel
Voici la procédure:
- Utiliser la fonction ALEA dans une colonne ajouter au tableau des coordonnées à choisir
- Copier coller en valeur le résultat de la fonction ALEA dans une nouvelle colonne
- Classer le tableau par ordre croissant selon la colonne créée à l’étape 2
- Choisir les n premiers points du tableau
4.2.1.2 Avec R
Voici comment tirer au hasard des positions dans l’espace à partir de la liste des pixels.
n = 20
#fixer la graine pour les tirages aléatoires
set.seed(5602)
# Creation des identifiants des lignes
id = 1:10000
# ou
id = seq( from = 1, to = 10000, by = 1)
# tire au hasard n valeurs parmi 10000
MesIds <- sample( x = id , size = n)
MesIds <- sort(MesIds)
# Les coordonn?es
champ[ MesIds , 1:2 ]## s1 s2
## 220 19.5 2.5
## 286 85.5 2.5
## 564 63.5 5.5
## 1631 30.5 16.5
## 1740 39.5 17.5
## 2202 1.5 22.5
## 2630 29.5 26.5
## 3105 4.5 31.5
## 3180 79.5 31.5
## 4063 62.5 40.5
## 5125 24.5 51.5
## 6048 47.5 60.5
## 6209 8.5 62.5
## 6355 54.5 63.5
## 7589 88.5 75.5
## 7666 65.5 76.5
## 7723 22.5 77.5
## 7897 96.5 78.5
## 8220 19.5 82.5
## 9119 18.5 91.5Il est possible alors d’extraire les valeurs de carbone simulée pour les pixels tirés au hasard
terrain1 <- champ[ MesIds, "sim1" ]
terrain1## [1] 5.088422 5.870447 4.565427 3.839903 4.177815 6.237273 5.100200 5.643163
## [9] 6.107451 5.163339 5.708381 6.154790 6.040184 6.388020 6.277084 5.526610
## [17] 6.171215 5.415374 6.536455 4.433357
4.2.2 Avec R pour les populations continues
1 Déterminer les coordonnées minimales et maximales s1 et s2 du domaine (boîte englobante)
2 Tirez deux coordonnées (pseudo-)aléatoires indépendantes \(s_{1,v}\) et \(s_{2,aleat}\)
Utilisez une routine de point dans le polygone pour déterminer si (\(s_{1,v}\),\(s_{2,aleat}\)) tombe dans la zone
Répétez les étapes 2 et 3 jusqu’à ce que n positions soient sélectionnées
Le package sp offrait la fonction spsample pour effectuer cette procédure à partir de couches SIG.
Nous utilisons ici la fonction spatSample du package terra
# MonEch <- spsample( x = champSP ,
# n = n ,
# type = "random")
MonEch <- spatSample(
champSP.terra,
size = n ,
method = "random",
na.rm = TRUE,
as.points = TRUE,
xy=TRUE,
values=FALSE
)
SI <- tm_shape(champSP.terra) +
tm_raster()+
tm_shape(MonEch)+
tm_symbols()+
tm_layout(legend.outside = TRUE)
SI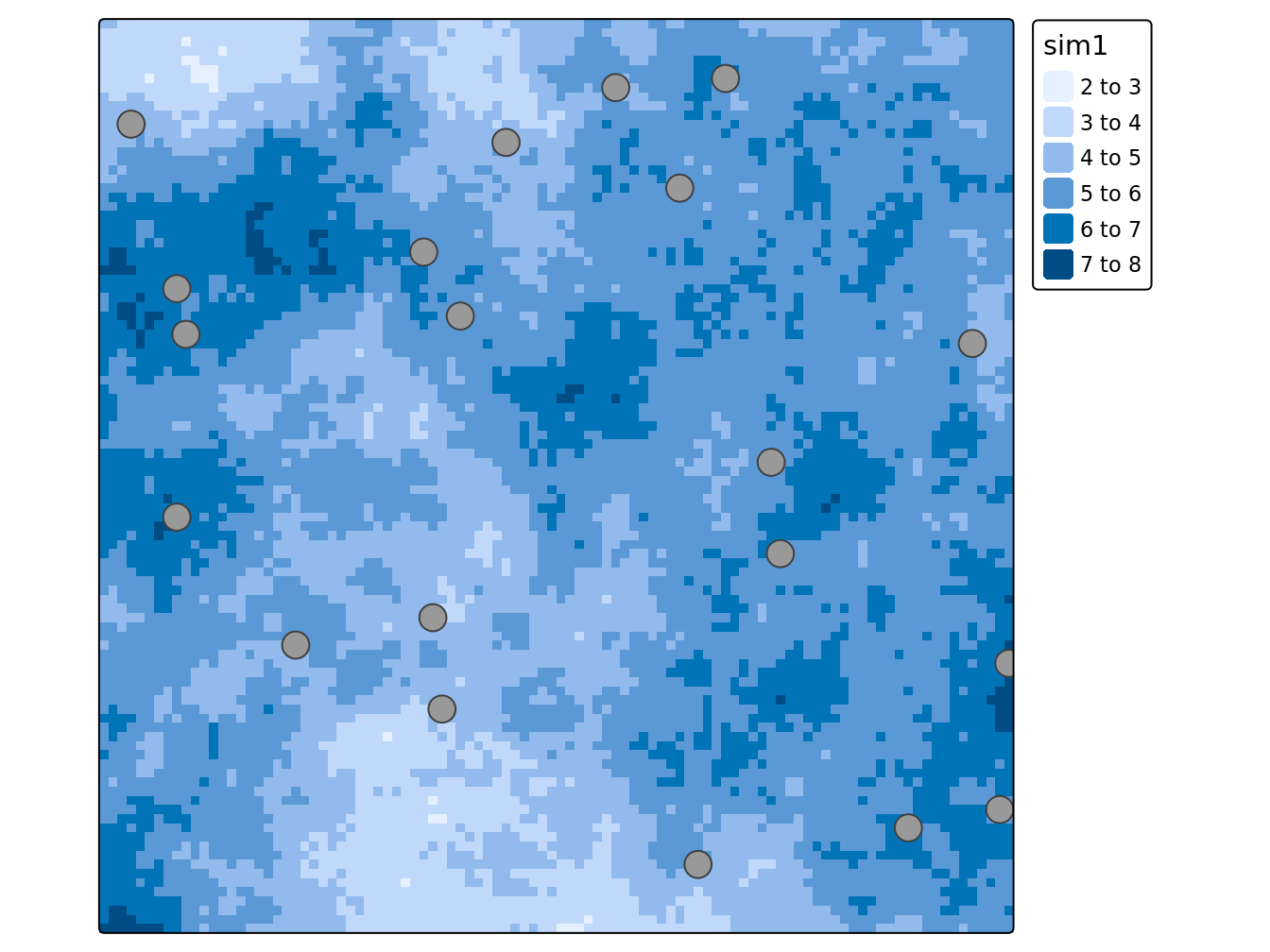
Figure 4.1: Exemple d’échantillonnage aléatoire simple, avec 20 points SI(20)
Le package sf qui remplace progressivement sp contient la fonction st_sample.
MonEchSF <- st_sample(
x = as(champSP,'sf') ,
size = n ,
type = "random")
SI <- tm_shape(champSP.terra) +
tm_raster()+
tm_shape(MonEchSF)+
tm_symbols()+
tm_layout(legend.outside = TRUE)
SI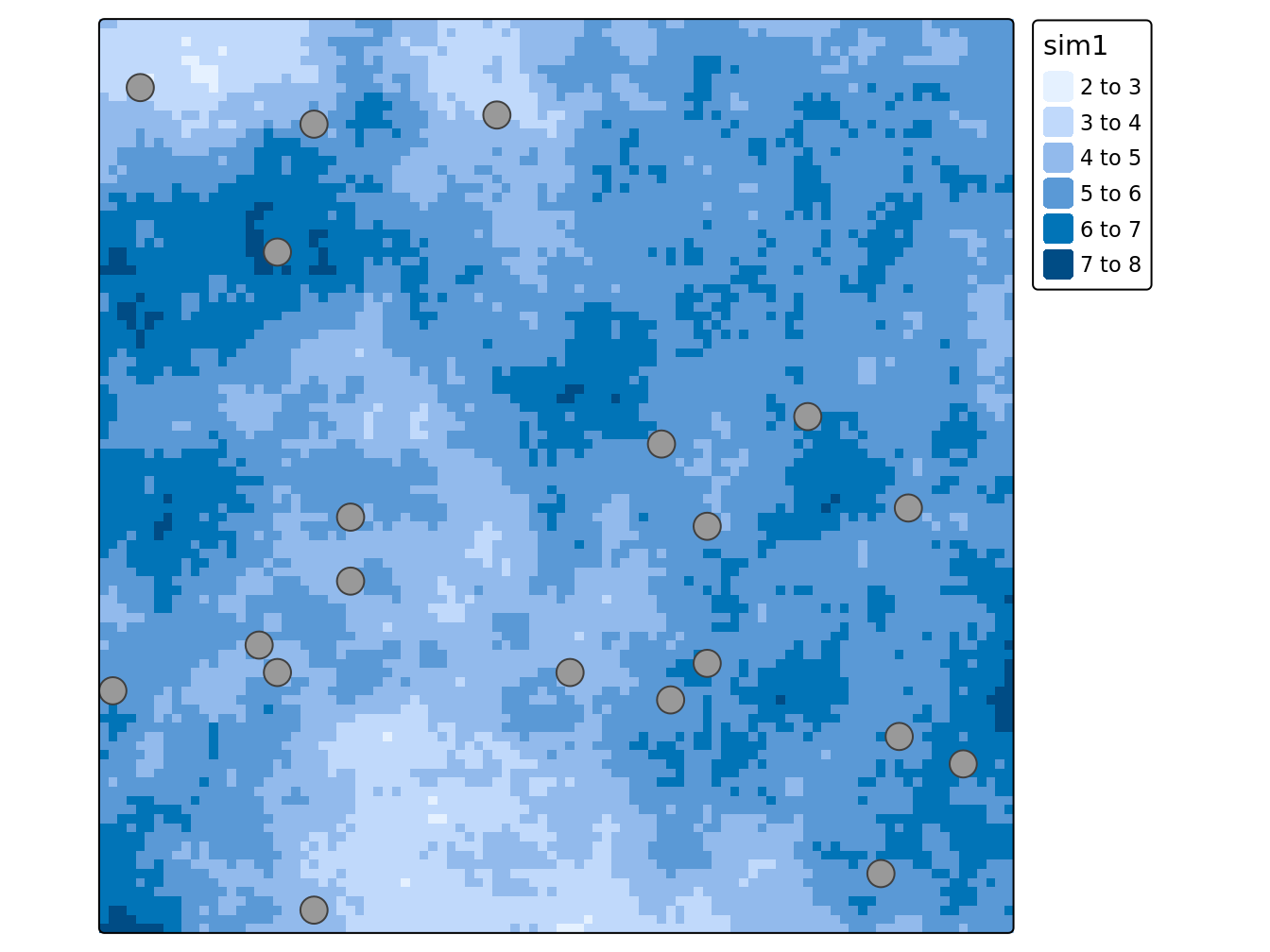
Figure 4.2: Exemple d’échantillonnage aléatoire simple, avec 20 points SI(20), avec le package sf
4.3 Calcul des estimateurs
Dans cette partie nous explorons les techniques pour calculer les estimateurs des paramètres statistiques à partir des données collectées.
4.3.1 l’estimateur de Horvitz-Thompson
L’estimateur H-T du total est \(\hat t = \sum{z_i/\pi_i}\)
L’estimateur H-T de la moyenne est \(\hat{\overline{t} } = 1/N\sum_{i=1}^n{z_i/\pi_i}\)
\(\pi\) est la probabilité qu’un site d’échantillonnage soit inclu dans l’échantillon (probabilité d’inclusion)
\(z_i/\pi_i\) s’appelle les valeurs étendues
Cette formule fonctionne pour n’importe quel plan d’échantillonnage avec \(\pi_i\) connus
Pour un SIR, la probabilité qu’un site soit choisi pour un tirage vaut \(1/N\)
avec \(n\) tirage, elle vaut \(\pi_i = n/N\)
Le total peut donc être estimé par \(N/n\sum_{i=1}^n{z_i } = N \hat{z}\)
4.3.2 La moyenne pour la population discrète finie
Avec le plan aléatoire simple, le calcul de la moyenne est très simple
# simulation du terrain
# jointure spatiale dans le format sp...
terrain2 <- extract(champSP.terra , MonEch )
MoyEst <- mean(terrain2$sim1)
MoyEst## [1] 5.548377A comparer avec la moyenne de la population \(5.2986022\)
4.3.3 La variance spatiale et variance d’échantillonnage
Ne confondez pas la variance spatiale et la variance d’échantillonnage !
- La variance spatiale (variance de population) est une caractéristique de la population
- La variance d’échantillonnage est une caractéristique d’une stratégie d’échantillonnage, c’est-à-dire une combinaison d’un plan d’échantillonnage et d’un estimateur
Son estimation dans le cas d’un SIR pour une population dite infinie
\(\hat{V}(\hat{ \overline{z} } ) = \frac{\hat{S^2}(z) } {n}\)
soit
\(\hat{V}(\hat{ \overline{z} } ) = \frac{1} {(n(n-1))} \sum_{i=1}^n (z_i - \hat{ \overline{z} })\)
Mais l’estimateur peut être utilisé pour les populations finie
\(\hat{V}(\hat{ \overline{z} } ) = (1 - \frac{n}N) \frac{\hat{S^2}(z) } {n}\)
avec \((1 - \frac{n}N)\) correspondant à la correction pour les populations finies
# Variance d'échantillonnage de MoyEst
V <- var(terrain2$sim1) / n4.3.4 l’interval de confiance
Le calcul de l’interval de confiance sur la moyenne nécessite de faire une hypothèse sur la distribution de \(\hat{ \overline{z} }\)
- Pour le un nombre \(n\) grand (>30) et si la distribution de la propirété dans l’espace n’est pas trop asymétrique, l’hypothèse de normalité est réaliste
L’intervalle de confiance à \(100(1-\alpha)\) % est:
\(\hat{ \overline{z} }\pm u_{1-\alpha/2}.\sqrt{V(\hat{\overline z}) }\)
où \[u_{1-\alpha/2}\] est le \((1-\alpha/2)\) quantile de la loi normale \(u\).
\(n\) is the number of sampling observations to compute the mean, eg \(n_h*H\).
- Pour des \(n\) petit (<30), la loi de Student est plus adaptée. on obtient:
\(\hat{ \overline{z} }\pm t_{1-\alpha/2}^{(n-1)}.\sqrt{V(\hat{t^l}) }\)
où \[t^{(n-1)}_{1-\alpha/2}\] est le \((1-\alpha/2)\) quantile de la loi de Student \(t\) avec \((n-1)\) degrees of freedom. \(n\) is the number of sampling observations to compute the mean, eg \(n_h*H\).
Voici comment le mettre en oeuvre dans \(`R`\)
# calcul du quantile
zalpha <- qnorm(p = 1- (0.05/2), mean = 0, sd = 1)
# si n est petit < 30
talpha <- qt(p = 1- (0.05/2) , df = n-1)
# calcul de l'interval de confiance selon les deux lois
IC <- zalpha * sqrt(V)
ICT <- talpha * sqrt(V)
c(IC,ICT)## [1] 0.3565736 0.3807810
# comme n< 30, on garde ICT
# Est-ce que la vraie moyenne est dans l'IC student
Moy < MoyEst + ICT## [1] TRUE
Moy > MoyEst - ICT## [1] TRUE
2 *ICT## [1] 0.7615621
resSI <- cbind(MoyEst,
ICT,
ICbas = MoyEst - ICT,
ICHaut =MoyEst + ICT,
Moy)
resSI## MoyEst ICT ICbas ICHaut Moy
## [1,] 5.548377 0.380781 5.167596 5.929158 5.2986024.4 Simulations d’un interval de confiance
Dans cette partie, nous allons tenter d’appréhender l’incertitude de l’estimation de l’indicateur à travers la réalisation de plusieurs échantillonnages simulés de 20 échantillons.
Pour cela, nous tirons au hasard 20 points 10000 fois et nous effectuons la jointure spatiale avec la couche SIG supposée représenter la réalité terrain.
n = 20
rep = 2000
# MonEch <- spsample(
# champSP ,
# N ,
# type = "random"
# )
library(foreach)
terrainSimulTOT <- foreach( i = 1:rep,
.combine = rbind.data.frame
) %do% {
MonEch <- spatSample(
champSP.terra,
size = n ,
method = "random",
na.rm = TRUE,
as.points = FALSE,
xy=TRUE,
values=FALSE
)
# on récupère les valeurs de carbone
terrainSimul <- extract(champSP.terra ,
MonEch )
resu = cbind.data.frame(
id = i ,
sim1 = terrainSimul$sim1
)
resu
}On calcule ensuite, par réplication, les estimations de la moyenne, de la variance d’échantillonnage et de l’interface de confiance de la moyenne.
MesMoys <- aggregate(terrainSimulTOT$sim1,
by = list(terrainSimulTOT$id),
FUN = mean)
MesVarsEch <- aggregate(terrainSimulTOT$sim1,
by = list(terrainSimulTOT$id),
FUN = var)
MesVarsEch$x <- MesVarsEch$x / 20
MesStats <- cbind.data.frame(MesMoys,MesVarsEch$x)
colnames(MesStats) <- c('Group','Moy','VarEch')
MesStats$UCI <- MesStats$Moy + talpha * sqrt(MesStats$VarEch)
MesStats$LCI <- MesStats$Moy - talpha * sqrt(MesStats$VarEch)Pour se rendre compte de l’intervalle de confiance à 95 %, nous représentons sur le graphique suivant pour les 100 premiers tirages, les estimations de la moyenne, et de son intervalle. Nous représentons également la vraie moyenne calculée sur tous les pixels: \(5.2986022\)
ggplot(MesStats[ MesStats$Group %in% 1:100 , ]) +
geom_pointrange(size = 0.62,
aes(x = Group, ymin = UCI, ymax = LCI, y = Moy)) +
geom_abline(intercept = Moy, slope = 0, color = "red")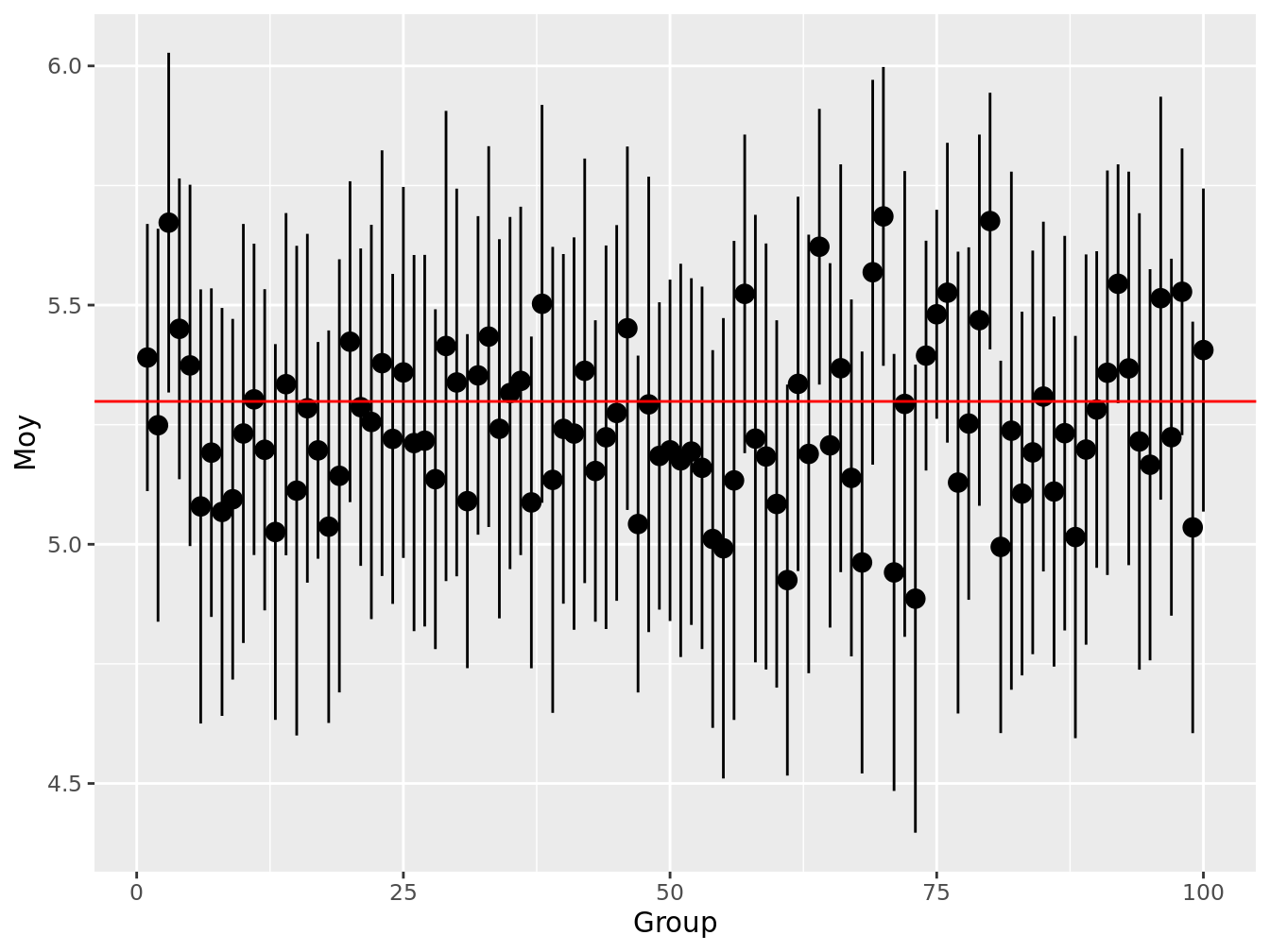
Figure 4.3: Représentation de l’intervalle de confiance à 95 % et de la vraie moyenne en rouge pour chaque simulation
Enfin, il est possible de calculer sur l’ensemble des réalisations, le nombre de fois que la vraie moyenne tombe en dehors de l’intervalle de confiance. Ce qui donne :
MesStats$test <- ifelse(Moy > MesStats$LCI,
ifelse(Moy< MesStats$UCI,
1,0),
0)
100* sum(MesStats$test)/rep## [1] 94.45OUI, 95 % comme attendu !