5 L’échantillonnage aléatoire stratifié
Pour ce type d’approche, la population ou la zone d’étude est subdivisée en sous-populations, appelées strates.
- Les strates ne peuvent pas se chevaucher, et leur union doit correspondre à la population étudiée.
- Dans chaque strate, un échantillon est sélectionné au hasard
- Les strates peuvent être échantillonnées de nombreuses manières, par exemple par échantillonnage aléatoire (SI). Cela conduit à un échantillonnage aléatoire simple stratifié (STSI)
- La méthode de sélection des unité par SI est appliquée à chaque strate séparément
5.1 Pourquoi stratifier ?
Deux raisons possibles :
- Les estimations des paramètres statistiques pour la zone sont plus précises
- Nous voulons des estimations séparées des paramètres statistiques pour les sous-populations
5.3 Estimateurs STSI
L’estimateur de la moyenne STSI est le suivant
\(\hat{ \overline{z} } = \sum_{h=1}^{H} w_h \hat{\overline{z} }_{h}\)
avec \(w_h = A_h/\sum_{h}A_h\) et \(\hat{\overline{z} }_{h}\) est l’estimateur SI de chaque strate \(h\) avec un échantillonnage aléatoire simple.
La variance d’échantillonnage de la moyenne expérimentale des \(z\) est :
\[\begin{equation} V(\hat{ \overline{z} } ) = \sum_{h=1}^{H} w_h^2 \frac{ \hat{ S^2_h} (\hat{ \overline{z} } ) }{n_h} \end{equation}\]
où \(\hat{ S^2_h} (\hat{ \overline{z} })\) est la variance SI dans la strate \(h\) :
\[\begin{equation} \hat{ S^2_h} (\hat{ \overline{z} })= \frac{1}{n_h-1}\sum_{i=1}^{n_h} ( z_{hi} -\hat{\overline{z}}_h ) \end{equation}\]
5.4 Stratification géographique par strates compactes géographiques
Parfois, il n’existe pas d’information a priori sur la variabilité spatiale de la propriété visée. Dans ce cas, une bonne répartition spatiale peut
5.4.1 Définition
Dans cette approche, les \(n\) observations sont réparties de manière optimale au sein de la zone d’étude. Pour cela, on utilise un critère qui minimise la distance entre les observations et un discrétisation de la zone d’étude. La moyenne du carré de la plus courte distance au point j:
\(MCPCD_j = 1/N \sum^N_{i=1}min_j(D_{ij}^2)\)
Le critère \(MCPCD_j\) peut être minimisé en utilisant l’algorithme des K-moyenne
Il existe un package R spcosa de Walvoort, Brus, and Gruijter (2010).
Dans cette appraoche, il n’est pas nécessaire de définir un variogramme a priori pour l’optimisation de la répartition des \(n\) observations. Les strates ainsi définies sont appelées Strates compactes
5.4.2 Estimateurs STSI
Ici, comme les strates ont la même surface et donc le même poids, on peut simplifier les estimateurs
En effet, on peut simplifier les poids : \(w_h = A_h/\sum_{h}A_h = 1/H\)
La moyenne:
\[\begin{equation}
\hat{ \overline{z} } = \sum_{h=1}^{H} \frac1H \hat{\overline{z} }_{h}
\end{equation}\]
et
\[\begin{equation} \hat{\overline{z}}_{h} =\frac1{n_h} \sum_{i=1}^{n_h}z_i \end{equation}\]
Si en plus le nombre d’observations est le même par strate (\(n_h\)), on obtient une formule assez simple
\[\begin{equation} \hat{ \overline{z} } = \frac1N \sum_{i=1}^{N} z_i \end{equation}\]
Pour la variance d’échantillonnage, il en va de même.
\[\begin{equation} V(\hat{ \overline{z^l} } ) = (\frac1H)^2 \sum_{h=1}^{H} \frac{ \hat{ S^2_h} (\hat{ \overline{z^l} } ) }{n_h} \end{equation}\]
5.4.3 Implémentation
Il est conseillé de tirer au hasard 2 points par strate afin de pouvoir calculer une variance. Il suffit ensuite d’adapter le nombre de strate pour atteindre le nombre d’unités d’échantillonnage visé.
Avec cette méthode, il est possible de répartir au mieux les unités dans l’espace.
Ici, on avait retenu 20 unités, soit donc 10 strates.
res(champSP.terra)## [1] 1 1
#aggregate from 1x1 resolution to 2x2 (factor = 2)
champSP.aggregate <- aggregate(champSP.terra,
fact = 2)
res(champSP.aggregate)## [1] 2 2
# il faut transformer en format grid sp
# pour cela il est possible d'utiliser un dataframe.
dt <- as.data.frame(champSP.aggregate,xy=TRUE)
coordinates(dt) <- c('x','y')
gridded(dt) <- TRUE
# compute compact geographical strata
myStrata <- stratify(dt,
nStrata = 10,
equalArea=TRUE,
nTry=5
)
spcosa::plot(myStrata)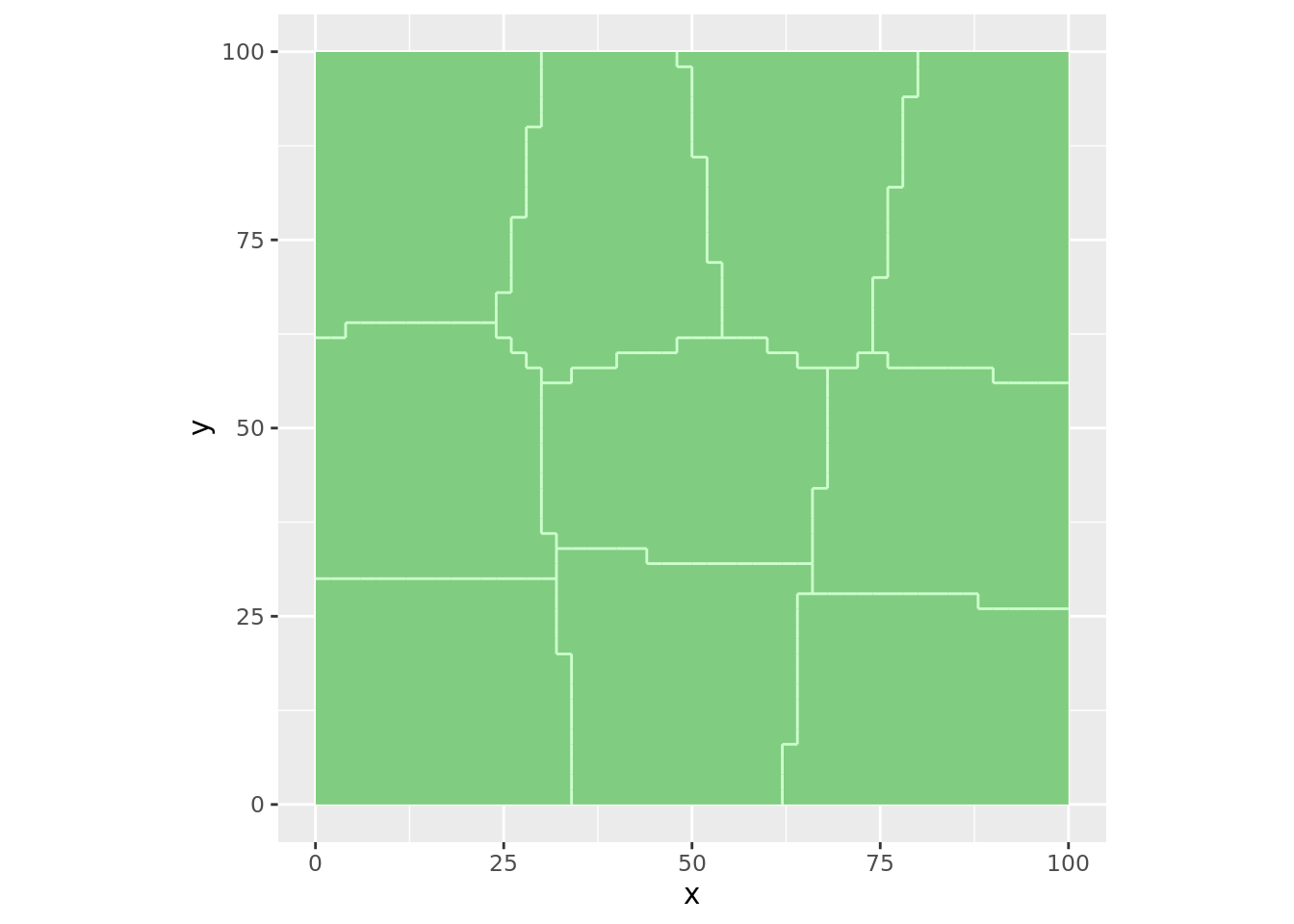
# obtain the surface areas of the strata
print(areaStrata<-getArea(myStrata))## 0 1 2 3 4 5 6 7 8 9
## 1000 1000 1000 1000 1000 1000 1000 1000 1000 1000
# select randomly n locations from the strata
mySample <- spsample(myStrata, n = 2)
plot(myStrata, mySample)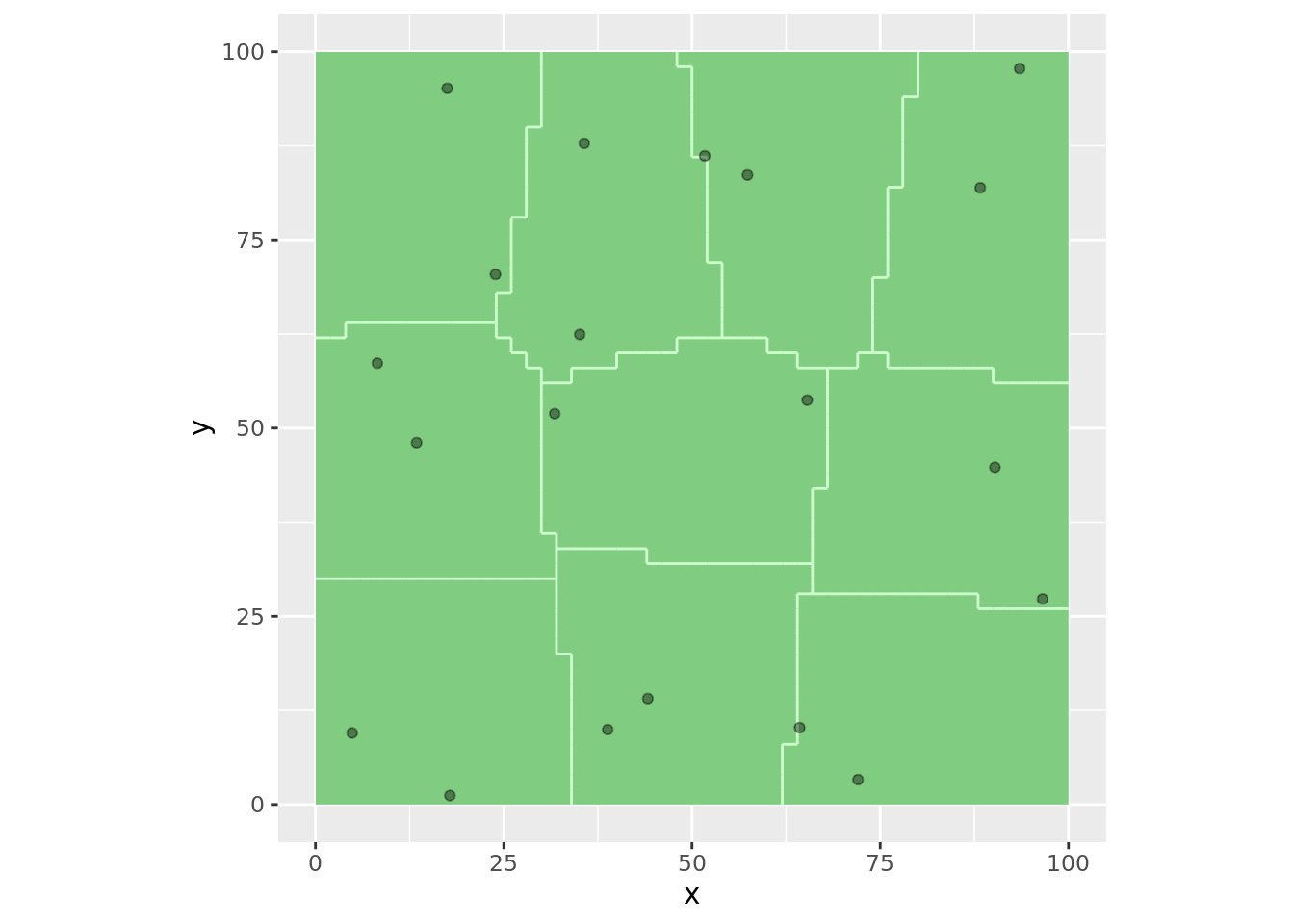
Comparons les deux approches: SI et STSI avec strates compactes
STSI <- tm_shape(champSP.terra) +
tm_raster()+
tm_shape( vect(mySample@sample) )+
tm_symbols()+
tm_layout(legend.outside = TRUE)
tmap_arrange(SI, STSI)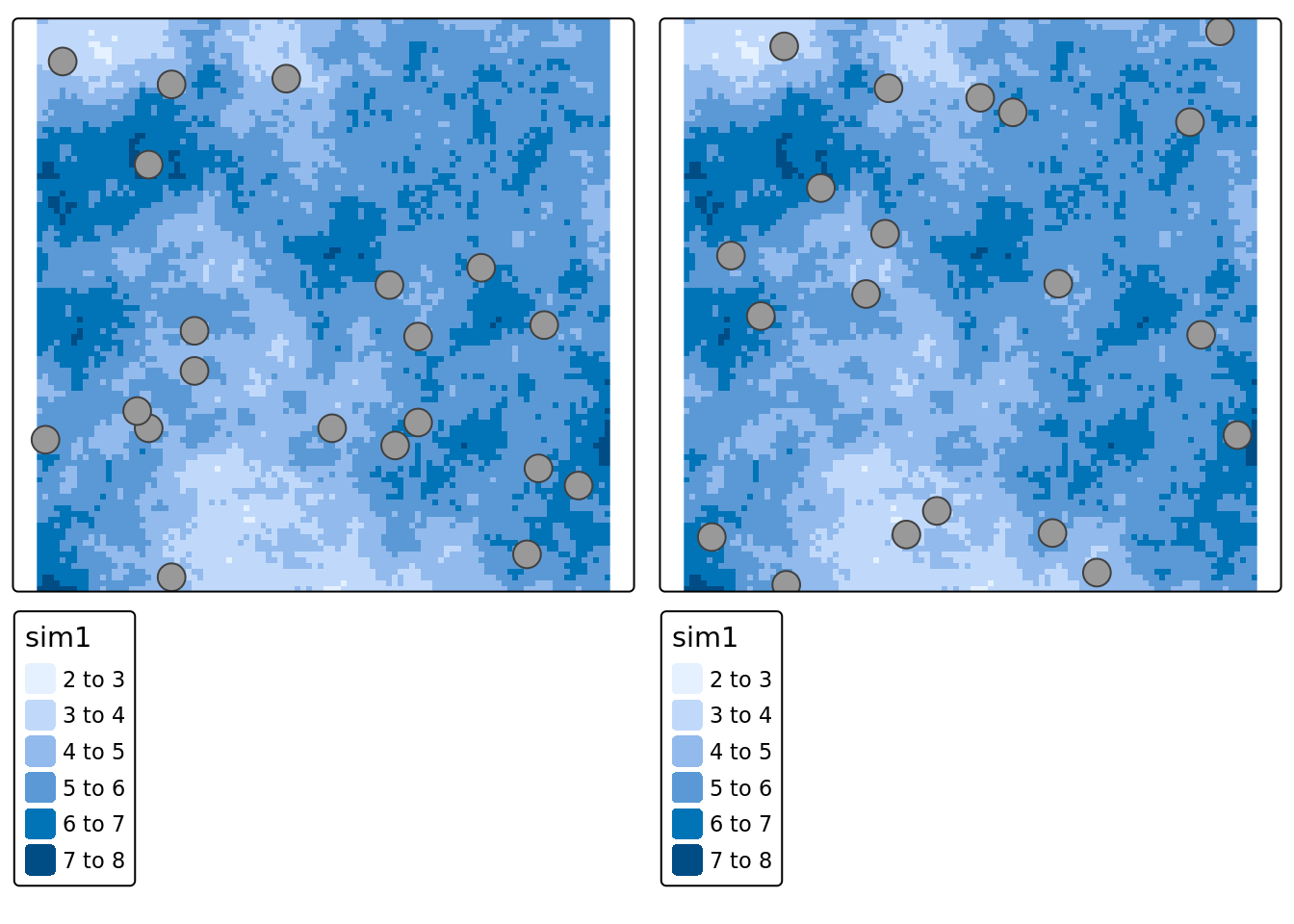
Examinons ce que donne la simulation pour le calcul de la moyenne. On interroge ainsi au droit des pixels les points d’échantillonnage. c’est une opération SIG classique. Puis, on calule la moyenne en utilisant l’estimateur classique.
terrainSTSI <- over(mySample@sample,champSP)
MoyEstSTSI <- mean(terrainSTSI$sim1)
MoyEstSTSI## [1] 5.169757Et pour la variance, il est nécessaire de calculer la variance par state et de calculer ensuite la moyenne pondérée de ces variances.
IL faut pour cela former un tableau qui rassemble les identifiants des strates pour chaque point. Nous allons récupérer ces informations avec une jointure spatiale.
#
StratesSTSI <- over(mySample@sample,myStrata@cells)
id <- as.numeric(row.names(StratesSTSI)) # les numéros des pixels
myStrata@stratumId[ id ]## [1] 0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9
Mydata <- cbind.data.frame(
strate = myStrata@stratumId[id],
z= terrainSTSI$sim1
)
Varh<-tapply(Mydata$z, INDEX=Mydata$strate,FUN=var)
VStsi <- (1/10^2) * sum(Varh/2)Voici donc la variance SI \(0.033098\) et la variance dans ce cas \(0.0373685\)
# calcul de l'interval de confiance selon les deux lois
ICT <- talpha * sqrt(VStsi)
# comme n< 30, on garde ICT
# Est-ce que la vraie moyenne est dans l'IC student
Moy < MoyEstSTSI + ICT## [1] TRUE
Moy > MoyEstSTSI - ICT## [1] TRUE
(resSC <- cbind(MoyEstSTSI,
ICT ,
ICbas = MoyEstSTSI - ICT,
ICHaut = MoyEstSTSI + ICT, Moy))## MoyEstSTSI ICT ICbas ICHaut Moy
## [1,] 5.169757 0.4046009 4.765156 5.574358 5.2986025.5 Stratification par stratification d’une donnée quantitative
5.5.1 Définition
Lorsqu’une covariable quanatitative est disponible en tous points de la zone d’étude, les strates peuvent être construite en utilisant la méthode appelée cum-root-f (voir Dalenius and Hodges (1959)).
5.5.2 Implementation
Dans notre cas, nous allons simuler une covariables à partir de champ
library(raster)
champSP.r <- raster(champSP)
cov <- champSP.r^2+champSP.r + 9*champSP.r/(1-champSP.r) +
rnorm( n = length(champSP.r@data@values) , sd = 2)
cov[cov<0] <- 0
plot(cov, main = "la covariable")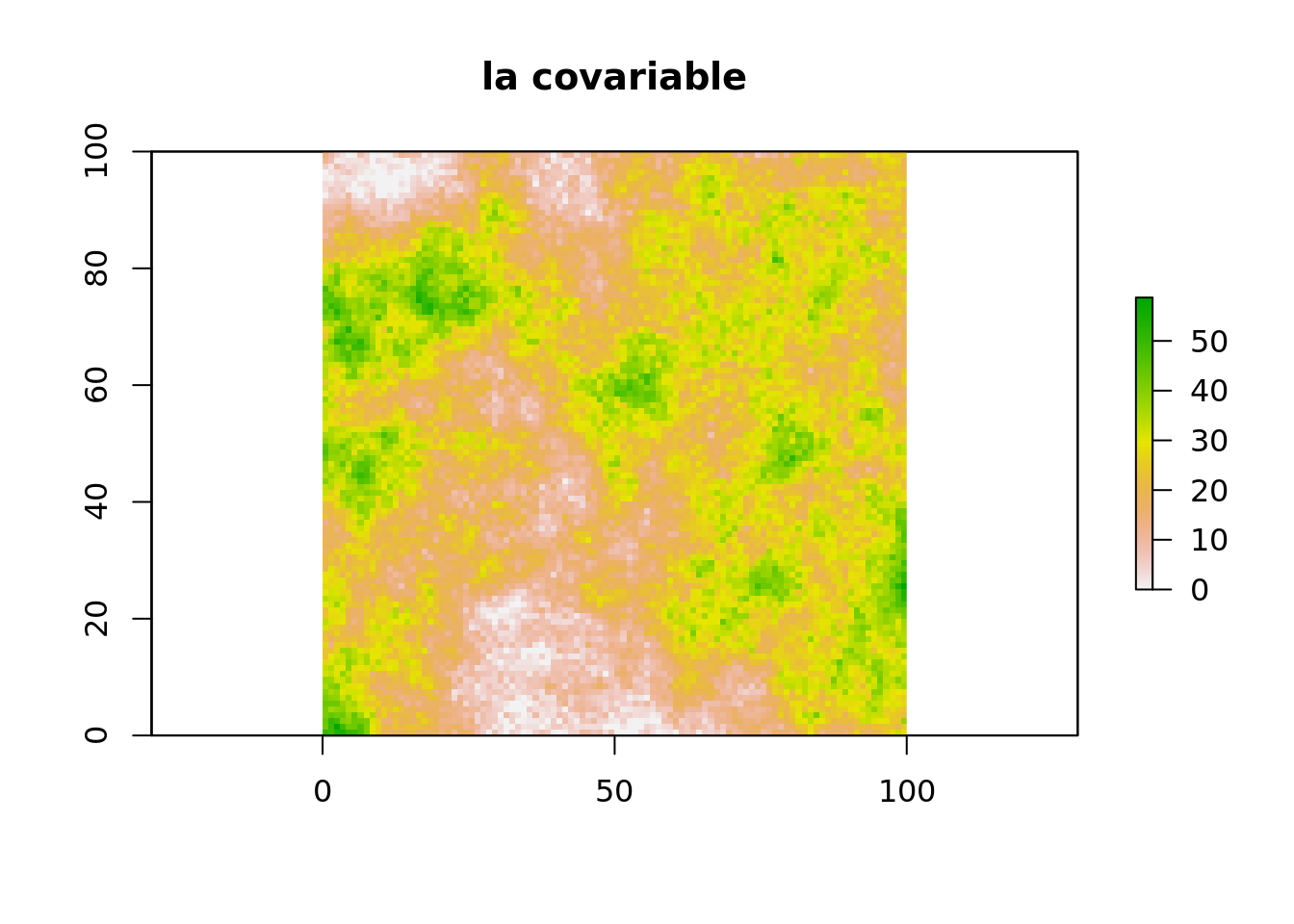
Les strates peuvent être construite avec le package stratification. Attention, les données doivent classer par ordre croissant avant la stratification.
En sortie, on dispose des limites des classes et de l’affectation de chaque observation à une strate.
library(stratification)
n.echantillons <- 20
n.strates <- 3
nclass <- n.strates * 100 #nombre de classes pour calculer l'histogramme
dt = cbind.data.frame(coordinates(cov),cov = values(cov))
dt <- dt[!is.na(dt$cov),]
dt <- dt[order(dt$cov),]
optstrata <- strata.cumrootf(
x = dt$cov,
n = n.echantillons,
Ls = n.strates,
nclass = nclass)
optstrata$bh #les limites des strates## [1] 17.81438 28.97284
optstrata$Nh #la taille des strates ## [1] 2905 4329 2766La figure suivante présente covariable dont la légende correspond à la limite des classes définies à l’étape précédente.
# dessin de la stratification
tm_shape(cov) +
tm_raster(
breaks = c(min(values(cov)),optstrata$bh,max(values(cov)))
)+
tm_layout(title = "la stratification",
title.size = 0.6,
legend.outside = TRUE) 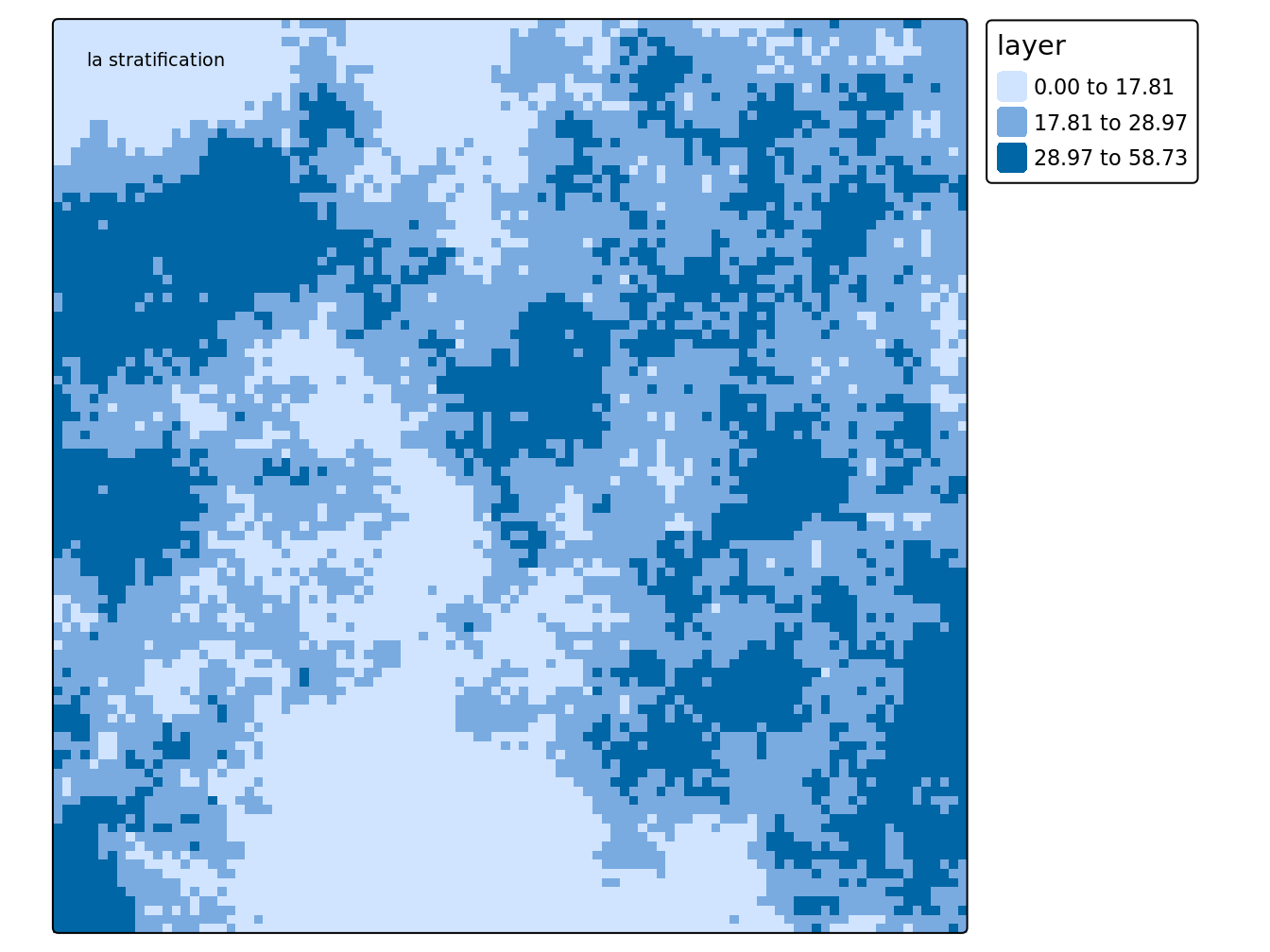
Figure 5.1: Carte des strates définies sur une variable quantitative
Ensuite, l’allocation des unités d’échantillonnage doit se faire au prorata des surfaces des strates. On nomme cela l’allocation de Newman. elle est idéal pour ce type de stratification
## [1] 6 9 6
sum(n_h)## [1] 21
n_h[1] <- n_h[1] + 1
#add optimal strata to data frame
dt$strate <- optstrata$stratumID
# on ajoute l'observation
dt$sim1 <- values(champSP.r)On tire au hasard ensuite une échantillon alétoire simple stratifié selon la répartition définie.
#select stratified simple random sample
units <- sampling::strata(
dt,
stratanames = "strate",
size = n_h,
method = "srswor")5.5.3 Estimation
Examinons ce que donne la simulation pour le calcul de la moyenne. cela consiste à interroger les pixels de la simulations comme dans la méthode précédente
mysample <- dt[units$ID_unit,]
mz_h <- tapply(mysample$sim1,
INDEX = mysample$strate,
FUN = mean)
(mz <- sum(w_h * mz_h))## [1] 5.216991Et pour la variance, il est nécessaire de calculer la variance par state et de calculer ensuite la moyenne de ces variances.
S2z_h <- tapply(mysample$sim1,
INDEX = mysample$strate,
FUN = var)
(v_mz <- sum(w_h^2 * S2z_h / n_h))## [1] 0.04280496
#The sampling variance can be computed without error from the population
S2z_h_pop <- tapply(dt$sim1,
INDEX = dt$strate,
FUN = var)
(v_mz_true <- sum(w_h^2 * S2z_h_pop / n_h))## [1] 0.02903045
#compute gain in precision due to stratification (stratification effect)
v_mz_SI_true <- (1 - n.echantillons / sum(optstrata$Nh)) * var(dt$sim1) / n.echantillons
(gain <- v_mz_SI_true / v_mz_true)## [1] 1.169397Voici donc la moyenne STSI \(5.2169908\) et la variance dans ce cas \(0.042805\)
# calcul de l'interval de confiance selon les deux lois
ICT <- talpha * sqrt(v_mz)
# comme n< 30, on garde ICT
# Est-ce que la vraie moyenne est dans l'IC student
Moy < mz + ICT## [1] TRUE
Moy > mz - ICT## [1] TRUE
cbind(mz,
IC = ICT,
ICbas = mz - ICT,
ICHaut = mz + ICT,
Moy)## mz IC ICbas ICHaut Moy
## [1,] 5.216991 0.4330333 4.783957 5.650024 5.298602Pour mémoire, voici le résultat pour les strates compactes
resSC## MoyEstSTSI ICT ICbas ICHaut Moy
## [1,] 5.169757 0.4046009 4.765156 5.574358 5.298602
resSI## MoyEst ICT ICbas ICHaut Moy
## [1,] 5.548377 0.380781 5.167596 5.929158 5.298602
5.2 Comment stratifier ?
Deux approches :
Stratification à l’aide d’un variables auxiliaires
Variable catégorielle (unités cartographiques)
variable quantitative (par exemple, images de télédétection, altitude, variables dérivées…)
Stratification par la position géographique uniquement (X et Y)