6 Echantillonnage aléatoire systématique
6.1 Définitions
En matière d’échantillonnage dans l’espace, le type d’échantillonnage appelé communément SY signifie un échantillonnage selon une grille régulière
Plusieurs points doivent caractériser cette grille
La grille est placée au hasard sur la zone. En général, on tire au hasard le point origine de la grille dans une zone de la résolution de la grille.
L’orientation ne doit pas être aléatoire
-
Dans les SY, les unités d’échantillonnage sont très bien réparties au sein de la zone d’étude
Avantage : (1) estimations précises du total, de la moyenne, de la proportion, et (2) il est possible de mettre en oeuvre des techniques de cartographie statistiques comme le krigeage.
Inconvénient : ils n’existe pas d’estimateur non biaisé de la variance d’échantillonnage
fixer le nombre de points avec la résolution qui va dépandre du budget alloué au projet.
6.2 Exemple de grille
set.seed(1) # ne marche pas sinon
# MonEch <- sp::spsample( x = champSP ,
# cellsize = 20 ,
# type = "regular")
x = st_sfc(
st_polygon(list(rbind(c(0,0),c(100,0),c(100,100),c(0,100),c(0,0))))
)
MonEch <- st_sample( x ,
type = "regular",
30)
set.seed(3) # ne marche pas sinon
MonEch2 <- st_sample( x ,
type = "regular",
30)
tm_shape(champSP.terra) + tm_raster() +
tm_shape(shp = MonEch) + tm_symbols(col='black') +
tm_shape(shp = MonEch2) + tm_symbols(col='green')+
tm_layout(legend.outside = TRUE)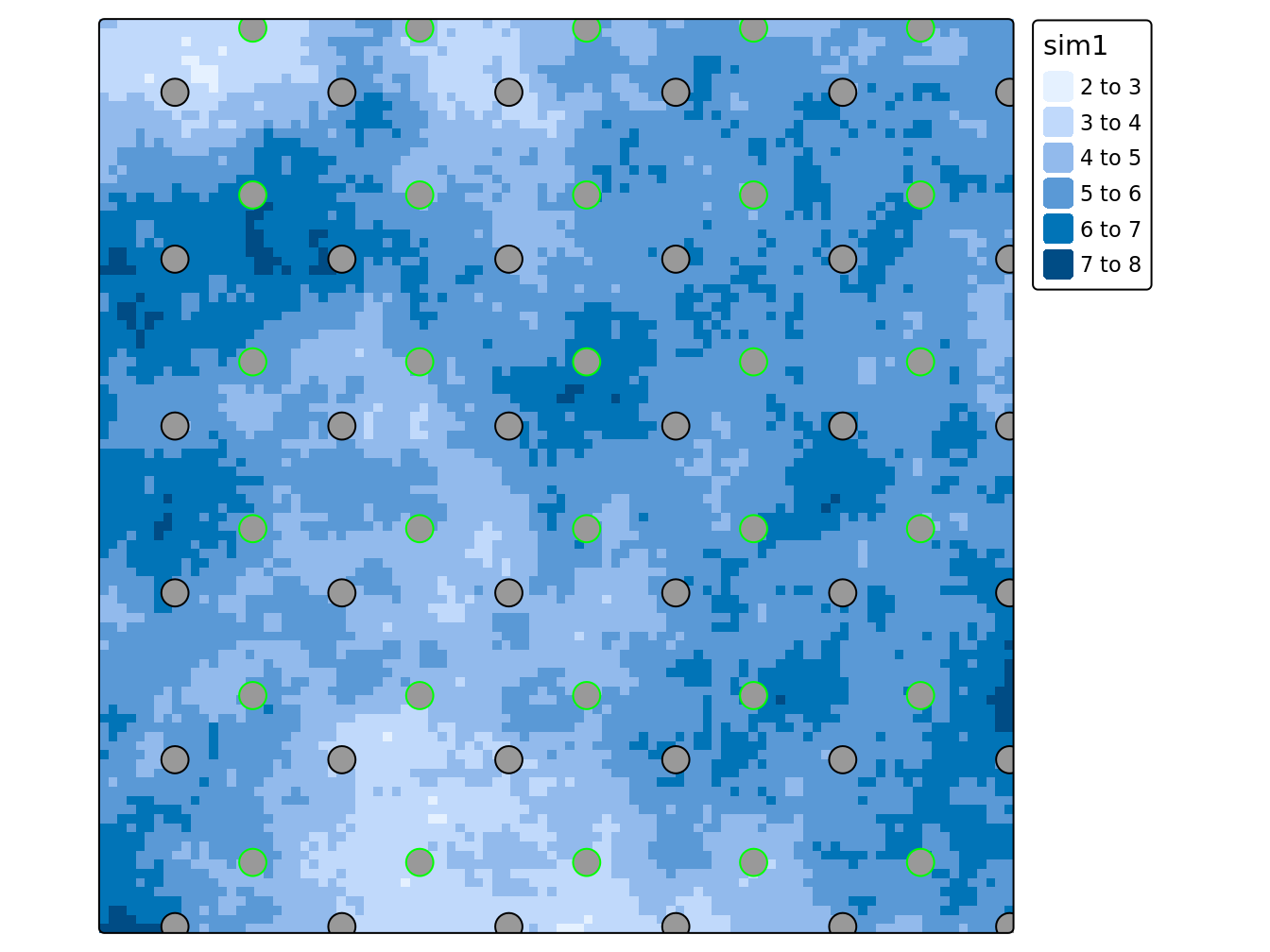
Figure 6.1: Exemple de grilles systématiques placées au hasard
6.3 théorie
La moyenne peut être calculé avec l’estimateur classique de l’échantillonnage aléatoire simple ou SI. la fonction mean de R.
6.4 Exemple de mise en oeuvre
Voici un exemple de mise en oeuvre des calculs proposés au paragraphe précédent.
# d'abord récupérer les valeurs au niveau des sites
terrainSY <- extract( champSP.terra ,
vect(MonEch2) ,
xy=TRUE
)Voici la fonction pour faire le clustering spatiale par groupe égale
.kmeans_equal_size <- function(s1, s2, k) {
n <- length(s1)
cluster_id <- rep(1:k, times = ceiling(n / k))
cluster_id <- cluster_id[1:n]
cluster_id <- cluster_id[sample(n, size = n)]
s1_c <- tapply(s1, INDEX = cluster_id, FUN = mean)
s2_c <- tapply(s2, INDEX = cluster_id, FUN = mean)
repeat {
n_swop <- 0
for (i in 1:(n - 1)) {
ci <- cluster_id[i]
for (j in (i + 1):n) {
cj <- cluster_id[j]
if (ci == cj) {
next
}
d1 <- (s1[i] - s1_c[ci])^2 + (s2[i] - s2_c[ci])^2 +
(s1[j] - s1_c[cj])^2 + (s2[j] - s2_c[cj])^2
d2 <- (s1[i] - s1_c[cj])^2 + (s2[i] - s2_c[cj])^2 +
(s1[j] - s1_c[ci])^2 + (s2[j] - s2_c[ci])^2
if (d1 > d2) {
#swop cluster ids and recompute cluster centres
cluster_id[i] <- cj; cluster_id[j] <- ci
s1_c <- tapply(s1, cluster_id, mean)
s2_c <- tapply(s2, cluster_id, mean)
n_swop <- n_swop + 1
break
}
}
}
if (n_swop == 0) {
break
}
}
D <- fields::rdist(x1 = cbind(s1_c, s2_c), x2 = cbind(s1, s2))
dmin <- apply(D, MARGIN = 2, FUN = min)
MSSD <- mean(dmin^2)
list(clusters = cluster_id, MSSD = MSSD)
}
kmeans_equal_size <- function(s1, s2, k, ntry) {
res_opt <- NULL
MSSD_min <- Inf
for (i in 1:ntry) {
res <- .kmeans_equal_size(s1, s2, k)
if (res$MSSD < MSSD_min) {
MSSD_min <- res$MSSD
res_opt <- res
}
}
res_opt
}
n <- nrow(terrainSY)
k <- floor(n / 2)
set.seed(314)
res <- kmeans_equal_size(
s1 = terrainSY$x / 1000,
s2 = terrainSY$y / 1000,
k = k,
ntry = 100
)
terrainSY$cluster <- res$clustersPour approximer la variance, voici l’implémentation.
S2z_h <- tapply(terrainSY$sim1,
INDEX = terrainSY$cluster,
FUN = var)
nh <- tapply(terrainSY$sim1,
INDEX = terrainSY$cluster,
FUN = length
)
v_mz_h <- S2z_h / nh
w_h <- nh / sum(nh)
av_STSI_mz <- sum(w_h^2 * v_mz_h)
semeanSI = var(terrainSY$sim1)Ainsi, l’estimation de la variance d’échantillonnage dite naïve est \(0.7027455\). Cette valeur est supérieure à la valeur fournie par l’estimation avec le deuxième formule: \(0.0268458\)